Tiletool
tiletool is a utility for map tile processing. It can generate lowzoom tiles combining higher zoom tiles, apply overlays over them and some other useful features.
Purpose
Low zoom tiles are much more expensive to render compared to higher-zoom ones, because with each zoom level towards 0 tile ares grows 4x, and so grows its complexity. Because of that, renderers have to ignore certain classes of objects when rendering lowzoom tiles and/or update these tiles less frequently. This is inconvenient, as detailed overview map is often useful, and outdated tiles are always bad.
This utility should help with that problem - in short, it does two things:
- combines higher zoom tiles into lower zoom tiles
- applies semitransparent overlays on them
With that, you can render tileset of, for example, zoom 8 without captions and icons, then render semitransparent tiles with only captions for this and lower zooms (which should be much less expensive than rendering all geometry), then combine them with tiletool into full-fledged detailed lowzoom tileset. For instance, this approach was used in osmarender.
-
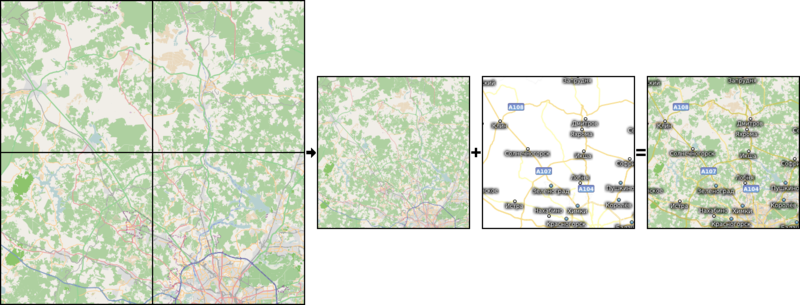 Illustration of a process (captionless tiles by toolserver.org, overlay by MapSurfer.NET)
Illustration of a process (captionless tiles by toolserver.org, overlay by MapSurfer.NET)

Getting and compiling
*nix
To compile tiletool, you need cmake and libpng.
% git clone git://github.com/AMDmi3/tiletool.git % cd tiletool && cmake . && make
It's known to work on at least Linux and FreeBSD.
Windows
Windows binaries are available from GitHub
Example usage
Note that tiletool operates with tilesets in common directory hierarchy zoom/x/y.png.
Generate zoom 0-7 tiles from a set of zoom 8 tiles (path/to/tiles contains 8/0/0.png ... 8/255/255.png)
tiletool -z 8 -i path/to/tiles -o path/to/output
Same, and also apply overlay
tiletool -z 8 -i path/to/tiles -o path/to/output -l path/to/overlay
Same, but do it in parallel, and also postprocess tiles with optipng to reduce size:
tiletool -z 8 -i path/to/tiles -o path/to/output -l path/to/overlay -c 'optipng -o1 -quiet' -j 16
Performance
It took 12 minutes to produce z0-z8 tiles (87k files) from z9 on Core i7-2600K CPU, with -1 -j16 -c 'optipng -quiet -o1' options, no overlays used. Despite -j 16, it hardly loaded 2 cores, so bottleneck is likely reading and combining tiles (which is not paralleled) rather than compressing and optimizing output (which is). If different approach to parallelization is taken (instead of individual tiles, process tile subtrees in parallel), the speed thus may be significantly improved, but I find it sufficient for now.