Overpass API/Technical details
Servers status · Versions · Development · Technical design · Installation · XAPI compatibility layer · Public transport sketch lines · Applications · Source code and issuesOverpass turbo · Wizard · Overpass turbo shortcuts · MapCSS stylesheets · Export to GeoJSON · more · Development · Source code and issues · Web siteOverpass Ultra · Examples · Overpass Ultra extensions · MapLibre stylesheets · URL Params · more · Source code and issues · Web site
On this page I draft some considerations and experimental conclusions in the software design of Overpass API that may be relevant to other OSM databases. The first version is a translation of the background article in the FOSSGIS 2012 Tagungsband (in German).
Harddisk latency: the real bottleneck
Note: Overpass API typically runs on SSDs nowadays.
A first version of Overpass API in 2008 was based on a conventional relational database, the MyISAM engine of MySQL. This was painfully slow. Reading a million lines out of a table has taken rougly 600 seconds, even after optimization with the best possible SQL library of MySQL. By contrast, the custom made backend, Template DB, needed only 3 to 5 second for the same job.
To understand this difference, one needs to know more about the design of database backends: The data itself is stored per line at a specific place of the harddisk. Newly inserted lines take the spaces left over by deleted lines. To make some dozen or hundred lines fastly accessible, special data structures, the so called indices, are stored on disk or in memory. There is usually more than one index to speed up various types of searches, and the careful selection of indices contributes much to the performance of the database. For simplicity in the following, we assume there is only one index. With multiple indices, things are in fact either the same or getting worse.
The dominant amount of time is taken by jumping to the various positions of the file on the harddisk. A relational database is therefore geared to have at best only one disk seek operation per line. If every combination of lines is equally probable as the result of a search, this strategy can be proven to be optimal.
However, this assumption is vastly wrong with OSM data. Usually, large numbers of spatially close nodes are queried more often together than sparse scattered nodes. Thus, Template DB organizes groups of spatially close nodes together in blocks of data. Given the typical times for seeking (0.1 second) and reading (50 MB per second) this is faster than the relational design even if only 0.1 percent of the read data is actually relevant for the query!
To make spatial proximity accessible to OSM, the data is indiced by a room-filling curve. By benchmarking, a block size of 512 KB has turned out to be fastest.
A lucky side-effect of this block design is that it is treated very gently by the caching strategies of at least the today Linux: more than 99% of all read accesses to blocks are satisfies from cache instead of the harddisk. See the munin stats: although the ratio of outgoing to ingoing traffic is between 100 to 1 and 500 to 1, twice more write accesses are performed than read accesses.
Room-filling curve
The resolution of coordinates in OpenStreetMap prefers a certain implementation: latitude and longitude can be stored each very efficiently in a 32 bit integer. In fact, the latitude uses only 31 bits, only the longitude uses the full 32 bits. To make a room filling curve[1][2][3] out of it, we bitwise interleave latitude and longitude. As index, the upper 32 bits are used.
-
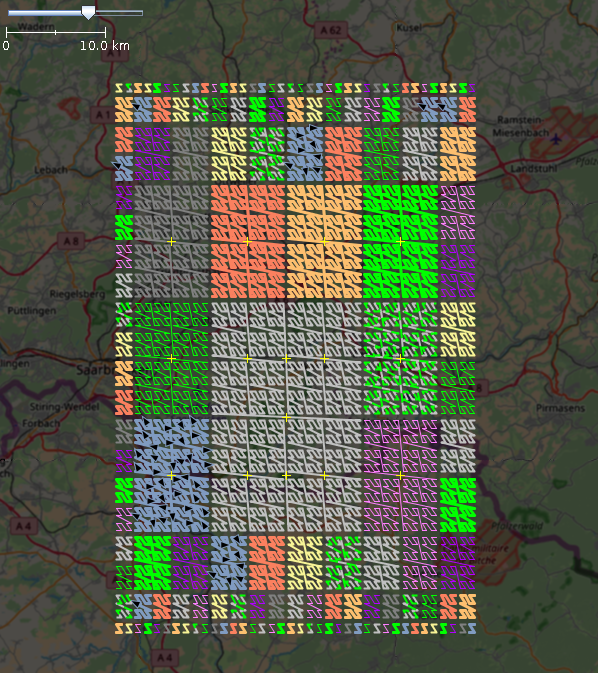 All 316 ranges which have been created for bounding box (49.0, 49.5, 7, 7.5), matching Z-Order Room filling curve
All 316 ranges which have been created for bounding box (49.0, 49.5, 7, 7.5), matching Z-Order Room filling curve -
 Room filling curve detail
Room filling curve detail


To also index objects with spatial extend, namely ways and relations, this concept has to be slightly extended. For this purpose, the upper bit is used to mark an index as a compound index; the index taken is roughly the south western corner of the object's bbox, and the lower bits of the index carry information about the size of the bounding box. Thus, each way is stored in relative proximity to the nodes it refers to. Thus, only few locations on the harddisk must be searched for features that may be present at a certain location.
Organizing by type
Another factor 2 to 10 comes from separating different types of data in an object. Overpass API can only be of widespread purpose if it stores all kinds of OSM data. But different kinds of queries require different subsets of the total data: rendering geometry doesn't require neither tags or meta data, and several use cases of further processing like general rendering, routing, and search at least don't require meta data. But these make a majority of all data by volume (database as of 23 Feb 2012):
- 29% are structural data (geometry and element memberships)
- 7% tag data
- 47% meta data (timestamp, version, changeset id, user id)
- 18% auxiliary data to make some queries faster
Separating meta data has brought a speedup of a factor of 3 where not needed. Likewise, separating tag data from the remainings brought a significant speedup. This observation is the reason to keep the different kinds of data separated.
Transactionality
Overpass API ensures transactionality, that is that a query always is based on a consistent data set, by shadow copies.
The design of the management system with one running process allows only one writing process in parallel, because that suffices for the OSM replication system.
Other topics worth documenting
- Template DB: map / bin files, index files, compression. Groups, segments, allocation strategies, void handling
- Index calculation algorithm, way <> nodes parent child navigation
- Areas / Polygon queries: algorithm
- Dispatcher: architecture, rate limiting, high level supporter command overview
- Backend: database updates, including Attic, node, way, relation, meta updates, merging
- Query execution pipeline