API v0.7
Since April 2009, the current version of the OpenStreetMap editing API is 0.6. Multiple backwards compatible changes were made afterwards without increasing the version number. API v0.7 is a general term for proposed changes. Noting an idea on this page will not necessarily result in an implementation. Most of the following ideas are even rather unlikely to be implemented. The list can be though of as a result of a brainstorming session.
| In 2022, the Engineering Working Group has 'commissioned' a study to investigate potential changes to the OSM Data Model. Read more about it here: https://github.com/osmlab/osm-data-model |
Does not require API 0.7
Not everything requires a new API version: Remember that any change that can be introduced without disrupting existing clients does not have to wait for API 0.7, or might also be implemented at any time after API 0.7 and before API 0.8 (or 1.0 for that matter). The only things that must be done in a concerted version upgrade are those that break compatibility or make it otherwise undesirable to continue using old clients. A simple "let's add feature X" which does not influence how everything else works does not really have to go here. One of the next steps after brainstorming would be to categorise features into (a) those that can only be implemented with an API change and (b) others; afterwards a subset of (a) is going to be selected for 0.7 (plus lots of things that are not on this list but relevant people come up with in the pub on the day before the switch), and some things from (b) might also be added but they won't critical in any way.
ALSO: Maybe we should separate "API" from "Data Model". The API does have some data model inspired calls (like /node/1234 etc.) but most really don't depend on the data model, and vice versa.
Allow handling messages via API
Currently it is possible to check number of unread messages. It would be better to allow receiving, sending, deleting, marking as read/unread via API Bulwersator (talk) 12:27, 2 November 2013 (UTC). See Messaging API proposal.
Binary protocol
As much as we love the current xml protocol it is source of many problems in some scripts. The xml have to be parsed into memory and written to the output file. This takes up much CPU, memory, space and transfer. If we ware to make a binary protocol we could eliminate most of the parsing and space issues.
Pbf is the format of choice now, but not available by the API, only as files--Jojo4u (talk) 23:47, 29 September 2016 (UTC)
- JSON was already added to 0.6, hence a binary protocol wouldn't require a move to 0.7 either. Mmd (talk) 20:11, 9 December 2020 (UTC)
Search for GPX-Tracks
We need the ability to search for GPX-Tracks which fulfil some criteria as supplied by name, description and tags.
- The should also include tracks intersection certain areas or within a certain distance of a requested position.
- This shall also include searching for tracks with a certain age (newer than the construction)
Better querying of changesets
If you click the history tab on the main page you get a huge list of changesets with a boundary box that intersects your area. This causes all the planet size changesets made by bots and careless humans to appear in every query even if nothing was changed in the requested area. The changesets query should only return the changesets which edited the requested area.
+1--Robotnic 14:43, 3 March 2010 (UTC)
- I second that. That's one of the first problems I noticed as a newcomer, and it's still a major pain. Tongro 11:00, 15 May 2010 (UTC)
- Good idea, but I would like to add a detail: Even if there is something changed inside the bounding box, it should be possible to get the subset of the changeset intersecting with the bounding box. The sketch mentioned above deals with the issue to get notice about a changeset that did NOT affect the requested area. It does not solve the change reports like "the changeset affected your area; have fun to find the single node inside within the 200k other elements". So: Give me the changes of changeset X inside bbox B, please. --Jongleur 17:51, 11 October 2010 (BST)
Improve history requests
The only way to get history information about a primitive is to request a full history via "/history". This can take some time with primitives having a long history. However, all users do not always want a complete history, and some statements could allow to get a partial history to speed up processing times, when not all is wanted.
- /short-history: Get only metadata information history (version and timestamp). This can be useful when a user wants to retrieve an object at a specified time, but does not know its version number. Currently we have to process entire history to find the good version. Instead, we could call short-history to retrieve only the version number, then call the "/#version" we want.
- /partial-history?min=A&max=B: Get only history information between version A and version B or between time T1 and T2.
--Don-vip 16:39, 28 December 2011 (UTC)
Readonly variant
Roughly 2/3 of the compressed data are due to username, user id, changeset id, timestamp and version, although they will be dropped at some stage for most usages, including mapping and routing. They are essentially only necessary to re-edit the data later on. On the other hand, large data sizes impede many use cases.
Dropping the data in an early stage and reducing data sizes is not always possible, because some clients do zealous checks whether the meta data is present. This could be fixed by a readonly variant: If readonly is flagged in the header, the processing tools shall not check for the presence of meta data. --- Roland.olbricht 08:54, 22 Oct 2011 (UTC)
- For re-editing, only the version number is essential, the remaining meta data (changeset, timestamp, user id, user name) are not necessary. I would suggest to leave the version numbers in the file and to drop changeset ids, timestamps, uids and user names. --Marqqs 12:40, 22 October 2011 (BST)
- the api isn't for read-only usage, it's for editing. so maybe all reply should have no changesetid/timestamp/user/uid unless requested (for ex history call) Marc marc (talk) 12:51, 7 May 2020 (UTC)
- Not actually. Tracking the authorship of content is a legitimate interest for a project that allows reuse of its content. Erkin Alp Güney (talk) 09:25, 13 March 2022 (UTC)
Prevent "Big" changesets
"Big" Changesets usually mean that an armchair mapper is trying to change the world to match their understanding of it. Preventing these from being submitted would force said armchair mapper to break down their changes geographically, making it easier for mappers submitting changes based on the outside world to know when a changeset affects anything that they've added.
An alternative (if this seems a bit drastic) might be preventing changesets larger than a certain size by new users (however "new" is defined). Users should "earn" the right to make progressively larger damage.
Changesets affecting one geographically large OSM item (e.g. a large relation) would still be allowed. - SomeoneElse 17:36, 11 March 2011 (UTC)
What is "big" here? Is it affected area or number of objects? Either way, such limitation would make large-scale fixups and cleanups harder to make and harder to revert (if an error is found after data is modified) if they have to be split into smaller changesets. Limiting only new users may be useful though (more for "number of objects" case, e.g. moving a large portion of data to an unaligned satellite image). - AMDmi3 23:56, 27 June 2012 (BST)
- Frequently raised issue although with unclear specifics. Could be done in API 0.6 already. Mmd (talk) 16:22, 11 December 2020 (UTC)
New Features
Node coordinate epoch
Each node in OSM contains a lat, lon and last modified date, but because fixed places on the ground are moving due to plate tectonics, when I re-survey the same place on the ground each year my WGS84 GPS coordinates will be different each time.
Therefore each node should optionally have an epoch value which is the time the coordinates were obtained. In the case of GPS coordinates it would be when the observation was taken (which may not be when the node was uploaded or modified). In the case of aerial imagery it will be the epoch that the aerial imagery uses. --Aharvey (talk) 12:05, 26 June 2020 (UTC)
- I move this to fun b/c of https://blog.openstreetmap.org/2017/03/31/osm-plate-tectonics/ Mmd (talk) 20:38, 9 December 2020 (UTC)
- Aharvey created an issue for this topic in the meantime: https://github.com/openstreetmap/openstreetmap-website/issues/3203 Mmd (talk) 13:41, 24 May 2021 (UTC)
- I'm moving this back to the API 0.7 section. There's absolutely no way to have such a change as part of API 0.6, b/c you need the buy in from the whole process chain (API, Planet files, diffs, and every single editing app), otherwise your attribute will either be silently discarded, not even exposed at all. Mmd (talk) 13:53, 24 May 2021 (UTC)
More intelligent history
When two ways are merged, only one history is saved (in the best case). When a way is split, only one way contains the history.
It would be better if objects have extra information. Something like an "comes_from" metadata.
Like if you merges ways with id 1111 and 2222 (say they are both at version 5), way 2222 would get deleted, and the next version of way 1111 would have as metadata 'comes_from="2222:5"' (way 2222, version 5).
When you look up the history, you arrive at version 6 of way 1111, and you see that you can chose which id to follow the further history of.
It also works when you merge more than 2 ways, in that case, just split the values with a ';'.
If you split way 1111 again, you create a new way with id f.e. 3333, and that way gets the metadata 'comes_from="1111:6"' (way 1111, version 6). So when you arrive at version 1 of way 3333, you can dig further in history via way 1111.
Just as the user id and the timestamp, the "comes_from" should be bound to the version. So if there's a new version of a way, without any merges or splits, the 'comes_from" metadata should be empty. --Sanderd17 15:45, 23 January 2013 (UTC)
It's often the case, that a way is split up into two or more parts to be able to apply different values e.g. for maxspeed or surface to the different parts - or even to add parts of the whole way to a relation only. Currently that's implemented in the following way:
- delete the nodes of one part out of the way
- create a new way object containing these nodes
- upload that
The problem with that algorithm is, that the new way starts with version 1; the history of the other way is not connected to this one any more.
The issue gets obvious at present inside the license discussion regarding "which ways are changed by ODBL/CC-BY-SA/PD only" etc; and there might be other issues as well; e.g. the source tag, mentioning the source of data has to be deleted, when a new changeset applies other sources to the object; but it should be possible to find every object anytime changed with a particular source. To achieve that, a unbroken history would be a good thing.--Jongleur 08:44, 16 November 2010 (UTC)
- Merging and splitting occurs on the editor level, rather than the API, and the editor is free to do pretty much anything. The API has no idea, how a new version was created, and we don't want to trust the client to provide accurate history information. Some downstream tools could use some heuristic to reassemble versions, but that would never be 100% accurate. Mmd (talk) 21:00, 10 December 2020 (UTC)
Areas
The support for areas in the OSM tool chain is still poor, although these are important. For example, ideas like downloading an area or country specific renderings require the existence of boundary polygons for countries.
But these boundaries are often disrupted by editing mistakes. For example, the boundary relation of Germany were not available during most of January. Other relations like the boundary of France have special formats due to their enormous complexity.
I suggest a data type that allows approximations. For example, a polygon with six vertices could enclose the "hexagone" France sufficiently to answer the question which motorways are in France and which not:
<relation id="11980">
<bounding-polygon>
<coord lat="51.5" lon="2.5"/>
<coord lat="48.5" lon="-6.5"/>
...
</bounding-polygon>
<inside>
<coord lat="51.0" lon="3.0"/>
<coord lat="48.5" lon="0.0"/>
...
</inside>
<member type="way" ref="..."/>
...
</relation>
|
Now we can derive that Paris is in France even if the border has a hole somewhere at Nice.
As these aren't nodes based on any real object, they should not be full blown nodes. Having them as values in tags won't work as they easily exceed 255 bytes. An automatic derivation of the intended polygon may not work in any advanced case or become very intricated, see Multipolygon.
Areas need their own data primitive as the definition as a closed way like today is errorprone. Also not every closed way is an area as the example of roundabouts shows.
Related:
Layers
Support for layers so that editors only receive certain types of data to limit work load on clients and server.
- Just allow the API to filter stuff, like OSMXAPI does. And keep in mind that a node may be shared between, say, a road and a fence... so if one of these features is not included in the downloaded data, it should be marked in some way, to let the editor know. --Ivansanchez 10:41, 2 February 2010 (UTC)
- I know it will be a PITA to store, but in theory a database query can return a list of objects that a node are members of, that way the editor can know if a node have other bindings than what is in the memory. On the other hand, it can make the memory load if the editor almost as big as if all the information was there, so that the workload part for the software (client side and server side) might not be altered. For the user on the other hand, when editing in areas with a high level of data, it can be a benefit to filter some parts of the data out. --Skippern 21:53, 4 March 2010 (UTC)
- Since the data is stored differently on the server than on the XML files commonly used by editors, an additional XML value can be added to show whether an object have unseen bindings when layering are used. i.e. a node can have <binding way="id#1,id#2" relation="id#3"/> telling the editor that if this node is edited, ways #1 and #2 and relation #3 should be consulted before uploading. --Skippern 21:18, 25 February 2012 (UTC)
- I know it will be a PITA to store, but in theory a database query can return a list of objects that a node are members of, that way the editor can know if a node have other bindings than what is in the memory. On the other hand, it can make the memory load if the editor almost as big as if all the information was there, so that the workload part for the software (client side and server side) might not be altered. For the user on the other hand, when editing in areas with a high level of data, it can be a benefit to filter some parts of the data out. --Skippern 21:53, 4 March 2010 (UTC)
- Overpass_API/Sparse_Editing already covers most of those requirements. Proposal to add additional flag would be incompatible with API 0.6 format. Mmd (talk) 20:42, 9 December 2020 (UTC)
Locks
"Verified" Users / Locked Tags
Some map features in OSM (e.g. borders) have an authority that officially or legally designates their location or path. These features should not be allowed to move except by verified users.
- This is against the idea of OSM, which is that everyone can improve an object. You can take a dump of your objects or set up your own database if you don't want them to be modified. This will cause only disputes, about which object should be locked and to whom are given the rights to modify them. So this is a bad idea. --Fabi2 19:33, 9 February 2011 (UTC)
- This can be implemented without change the spirit of OSM. Some features could be tagged with 'X' and editors would warn the user before change them. It would be a mechanism to prevent unwanted changes, but without limitating who really want to change them. Non-physical features, like administrative borders, could have that behavior. The approach I'm suggesting does not have any impact on the API. User:jgrocha, 10-Sep-2011
- Such a "lock" should be also available as an option to use on other tags. For example, if someone is definitly sure, that the information is correct, he could "close the lock" to prevent a cange by mistake (it can be unlocked by a confirmation (like described by User:jgrocha) and maybe the locking user gets a message). It should be possible to lock only one of the "features" of a nodes/way/..., including the possibility to only lock the latitude-postition of a node but let the longitude-position unlocked. (sorry for my bad english...) --rayquaza 06:02, 28 June 2012 (BST)
- I also agree that locking objects is (currently) not the way to go. There are other possibilities like monitoring campaigns (e.g. for worldwide borders in german forum), or pre-processing data (e.g. coastlines).--Jojo4u (talk) 23:39, 29 September 2016 (UTC)
Lock regions
I'd love that the API 0.7 could lock (small) regions if i am editing them. If another user want to modify then he can't if it is locked. However just a region of a maximum of 1 square kilometer should be locked by a user and a maximum of one lock should exist with a maximum duration of 1 hour.
Optionally a lock could be just a warning, that somebody else is editing the area already.
"Quarantine"
How about allowing users to mark a certain region as "under quarantine" or something in that spirit? When you are making large-scale changes in some region, like running an import or preparing to clean up some previous changeset gone horribly wrong, you do not want other users to interfere. "Quarantine" should
- not prohibit other users from editing, but only make the editor display a warning, including free text by the user issuing the quarantine
- expire automatically, e.g. after 24h, so people can't block their home area forever
- be allowed only for regions up to a certain extent
- perhaps not be available to all users, but only on request (if the user has enough experience, the feature may be activated for him, e.g. by the DWG or an admin)
--Oli-Wan 10:43, 13 January 2011 (UTC)
Lock feature
To prevent vandalism, local chapter/group of experienced local mappers would say that e.g. motorways are finished in given area. No one would be allowed to change/add new motorways. To change this lock, the same group would remove this lock. This would prevent inexperienced mappers from biggest mistakes, trolls from drawing names with motorways and marketing experts from creating cities from pubs.
Lock would include
- area (multipolygon)
- element types that are finished
- maybe only geometry is locked and new tags are possible (eg. other language names)
examples:
- a country and place=city
- region and highway=motorway|trunk
- country and region boundaries
- region and coast boundaries
MichalP 14:31, 25 February 2012 (UTC)
- This in reality is a DoS on updates feature! This should be fixed by better change tracking and reverting systems instead. --Fabi2 01:09, 26 February 2012 (UTC)
- Not sure, every now and then somebody changes city names (on purpose) or destroys boundaries (usually by accident). It is very time consuming and annoying. IMHO this will be needed sooner or later. --MichalP 17:15, 28 March 2012 (BST)
Monitoring
Users should be able to monitor a boundary box or a set of elements and be alerted when somebody edits them. This way edits gets verified by local mappers faster and there will be less vandalism.
- Not strictly something that needs to be implemented on API level. Could be done by external tools as well. Mmd (talk) 09:33, 12 December 2020 (UTC)
180th meridian
Perhaps allowing for nodes to have a longitude a bit greater then 180 to allow ways to connect properly and do some magic in the getters to make them appear on the 0 longitude.
- +1 So that the date-line, and borders that crosses the 180 can be correctly handled by the API, routing, and rendering without fancy workaround. Allow queries to seamlessly pass 180, i.e. with bbox values >180 --Skippern 18:52, 17 December 2009 (UTC)
- +1 See https://trac.openstreetmap.org/ticket/1612 and https://josm.openstreetmap.de/ticket/2212 --Don-vip (talk) 09:50, 30 October 2013 (UTC)
Undelete/undo
A proper undelete would be nice, so it would be possible to retain the old history of the object. If the undelete was implemented as undo, it would also work on visible objects, reverting them to the previous version without having to explicitly specify all the tags etc. of the old version.
- +1 This is definitively needed since the API 0.6 changes happened during redaction process. These changes basically killed the two (unmaintained) JOSM plugins that provided this functionality. A native undo/revert mechanism provided by the API would not be affected by any future API change. --Don-vip 22:27, 3 October 2012 (BST)
To fix vandalism and errors at least two minimum functions could be added:
- a way to find deleted objects in a given area (i.e. by delivering the last non-deleted state)
a way to request a certain "date" of the whole dataset (i.e. without knowing a special object or changeset)-> use Overpass API[date: ...]- both could be combined.
--Stoecker 20:37, 22 November 2012 (UTC)
Make it easy to keep track of parent objects
It would be good to be able to know if a node has been part of a way or a relation in the past ( and the same for ways belonging to relation ). Currently this is easy to get the information from the relation thanks to relation history but form the way or node itself this is not feasible without already having the information. -- [[User:Quicky|quicky] 2:29, 3rd Jan 2013 (UTC)
Tags for relation members. Role is not enough
For example, to map buildings that have many addresses:
<relation id="-1">
<member type="way" ref="-10" role="address">
<tag k="addr:housenumber" v="10/2"/>
</member>
...
<tag k="type" v="street"/>
<tag k="addr:street" v="Street 1"/>
</relation>
<relation id="-2">
<member type="way" ref="-10" role="address">
<tag k="addr:housenumber" v="2/10"/>
</member>
...
<tag k="type" v="street"/>
<tag k="addr:street" v="Street 2"/>
</relation>
|
--Liosha 15:35, 3 June 2010 (UTC)
- That can be fixed by tagging the addresses on the entrances. User:Lulu-Ann
- No it can't. Many houses here have addresses on several streets, and all entrances have all those house numbers. Alv 09:53, 4 June 2010 (UTC)
- Can't it be done with multiple relations? --Skippern 22:26, 4 June 2010 (UTC)
- I was saying just that house numbers on entrance nodes doesn't solve it. Multiple relations would make it possible. Alv 12:06, 6 June 2010 (UTC)
- It is possible: for example, you can make special relation "house_address" which has addr:housenumber tag and building as member, and itself is a member of street relation. But I think this way is too complex for comfort editing. Tags for members is better way --Liosha 09:47, 6 June 2010 (UTC)
- Can't it be done with multiple relations? --Skippern 22:26, 4 June 2010 (UTC)
- No it can't. Many houses here have addresses on several streets, and all entrances have all those house numbers. Alv 09:53, 4 June 2010 (UTC)
- +1 --Gorm 15:05, 7 June 2010 (UTC)
- tags for members would really make life easier in many cases. --Komяpa 16:48, 15 June 2010 (UTC)
- I'm also thinking about PT bus routes. The easiest schedules have starting times, and a fixed travel time to reach a certain stop. In those cases, the starting times could be encoded as a tag on the relation, and every stop could get a time showing how long it takes to get you from the start to that stop. It's possible with roles, though very clumsy. Encoding a schedule like this uses minimal information storage (not a whole 2D table, but just single values), which makes it easy enough to adapt. Even without starting times, it's handy, as it becomes easy to calculate the travel time from one stop to the next. --Sanderd17 (talk) 16:31, 11 February 2015 (UTC)
Relation can have large (a few hundreds) to very large (more than thousand) members. There is the need to give these large memberlists a structure. A comment is an entry in a memberlist, which does not reference any object but merely gives additional information on the kind/type of the following members. Examples:
- A relation defining a boundary for object AAA might sort the members such that all ways defining the boundary part which is common with the boundary of object BBB are put into a sequence wich is preceeded by a comment stating something like "boundary between AAA and BBB".
- A relation for a public transport route might arange the stop-position and platforms into sections from start to a central interchange node to another important interchange node to the to the end of the route. Each section is headed by a comment describing the following section.
- A relation describe the course of a long motorway might be split into section by the use of comments. Comments would thus allow to state that there are parts not yet build which therefor can't be part of the relation.
It is not essential to have comments in a memberlist but it is important to have a tool to give a memberlist an arbitratry structure. A comment in this respect is only a visible separator not a true structure.
- Comment can be modeled as key="note" value="comment" according to the same schema described here. No need for dedicated "comment" attribute. Mmd (talk) 17:12, 11 December 2020 (UTC)
Support for 3rd Dimension
The 3rd dimension is up to now only supported by the tags height=<number> and ele=<number> and proposed levels. But there are some things that aren't handled in a nice way.
- There is no provision for a digital elevation model (DEM)
- There is no provision for 3D-Objects like buildings which might have a lot of different height-values
- Buildings may have several parts with different height / number of levels.
- Even more complex are cathedrals with main and side naves, a transept, a apse and not to forget the tower(s).
- Multiple objects below or above each other like a parking ground below a shop or a parking area above a shop i.e. on the roof of the shop.
- The "several parts" point is covered by Simple_3D_buildings.--Jojo4u (talk) 00:00, 30 September 2016 (UTC)
- The below/above issue is currently solved for some common cases but not generally. E.g. parking=rooftop or location=underground for pipelines.--Jojo4u (talk) 00:00, 30 September 2016 (UTC)
Decoration
An intermediate step might be the introduction of decorations for buildings, which might be used to draw a 2D-representation of a building- or roof-shape.
- This is more a tagging issue and should be covered by Simple_3D_buildings now(?)--Jojo4u (talk) 23:56, 29 September 2016 (UTC)
3D, or 2.5D
This one's a long shot: allow for a z coordinate. Either adding 3D primitives, or making nodes a 2.5D primitive and working on that. Yes, it will drive Potlatch users crazy in high-density areas. Yes, it will drive validating tools crazy. But, hey, it will allow the Japanese guys to properly map those horrendous multi-level buildings with roads beneath them, and get rid of the infamous level= tag. --Ivansanchez 10:41, 2 February 2010 (UTC)
Support for Time-data
There are a few usage of time data for access restriction (date_on/off/...) and for modelling opening hours (shops, restaurants, offices service stations, ...). The next request is time data for public transport, in other words support for time-tables. There should be a scheme to handle all time data in a congruent way.
- Proposed features/Public transport schedules is a start.
Multiple Tags
The API should Accept the same Tag multiple times (again) and the whole toolchain must be changed to support this. This solves the whole "brand=VW;Kia" in a nice way: "brand=VW, brand=Kia".
There are a lot of internal things that does not support this like the posgres hstore but this could be solved by compressing the multiple tags into a single tag at import time (eg. in osm2pgsql or osmosis), but the main database should support this. MaZderMind 16:10, 11 October 2010 (BST)
Additional data validation
- Disallow single node ways
- Disallow ways with consecutive nodes
- Disallow empty relations
- Disallow blank tags
There are tons of relations without any members in the database. Most of them seem to have been created by accident. Those that have been added intentionally are perilously close to falling under [Relations are not categories] and there would be not much lost, if they disappear. So, the API should refuse to accept empty relations. Lonvia 18:05, 20 July 2011 (BST)
- Even if empty relations may be accidents most times now, they can also be used to more proper express things such as e.g. highway=service + service=driveway, which really means highway-->service-->driveway. Each tag is independent and there is nothing in the API to specify which tags belong to each other. This also leads to things like key:subkey:subsubkey=value or the use of ";" where a tree style key/tag-structure would be better to represent such things. I hope that this issue would be resolved in API 0.7, as for now empty relations are the only way to construct such trees to avoid the use of ";" in values (e.g. for cuisine=*). --Fabi2 00:46, 25 July 2011 (BST)
- Currently there are around 40'000 relations without any member, and 3156 relations without member + tags. Querying via Overpass is possible. Mmd (talk) 13:07, 15 April 2018 (UTC)
At the moment you can create a tag whose value is an empty string. These are not widely supported by editors and data consumers and all appearances in the database appear to be accidents or the result of editor bugs. Nothing would be lost making creating such a tag an error and reporting exising ones as keys not in use. Andrew (talk) 18:39, 21 October 2013 (UTC)
- +1 drolbr
- Seems to be a niche issue with only ~500 nodes, 400 ways and 50 rels affected. Mmd (talk) 16:56, 11 December 2020 (UTC)
Way to get orphaned relations and represent tree style information more properly
There is no good way in OSM to represent tree style information in an easy way, without relying on relations. You then have to use multiple parent/child-relation relations to represent this relaionships. If then some realtion in tis chain is orphaned, e.g. have no member objects and is not a member of an other relation any longer, then there is no way to get it back easily, if you you don`t know the relation id. A good way to represenbt tree style information is needed e.g. for the stop_area, route and route master relationship of public_transport=*. The same problem occurs e.g. for health care facilities. E.g. a hospital as the Berlin Charité have multiple departments distributed over localities in different suburbs. On these localities every building may contain an other medical speciality and maybe someone will map the rooms inside in the future. A tree data structure or some relaion extensions would also solve the misuse of the key to represent the objects child relationship as in
key:subkey_of_key:property_key_for_the_subkey=value
. --Fabi2 21:40, 30 December 2010 (UTC)
Additonal Comment to tree style tags
There exists many implicit tree style tags such as:
- highway=service + service=*
- type=public_transport + public_transport=*
- amenity=parking + parking=*
The problem is, that as more properties are added to an "map" object, as more difficult it becomeses to specify, to what feature of a "map" object a (overlapping) property belongs to. Only a simple example: is a university hosptal on a node or in the same building amenity=university or amenity=hospital? And what if the hospital is wheelchair=yes and the university only wheelchair=limited? Yes, until now you will then see something like hospital:wheelchair=yes and university:wheelchair=limited, while applications will only look for wheelchair=*.
Until now, the only clean solution is to use relations for this kind of tagging, but I don't think that realtions where not intended for this kind of misuse.
The problem is, that every tag can be theoretical combined with every other tag and sooner or later also would be. Tag A has no relationship to tag B, but this is, what a mapper would expect, if he use tags like power=* + power:*=* and other. --Fabi2 21:15, 11 April 2011 (BST)
Plain data scheme
Extend the data scheme to represent the intended structures directly instead of constructing them from "simple" parts in different ways. The current set of node,way,relation is meant to be simple - but it becomes very hard to comprehend when you try to describe more complex data. The means to represent it directly are missing, so people construct increasingly difficult workarounds. Those are very hard to understand for everyday mappers and nearly impossible to maintain.
Examples for needless complexity:
- using a way when you mean "area". Workaround is a tag "area=yes" which has caused a lot of confusion if and when it is needed. Problem on the nuisance level.
- Polygons/Multipolygons/Advanced Multipolygons: Three increasingly difficult concepts to describe the same thing: an area.
- Normal Polygon: The way describes an area, the way is the main object
- Multipolygon: The way describes an area, other ways are associated as holes with a relation. Main item is still the way. Harder to understand, error prone if you miss the relation
- Advanced Multipolygon: The relation describes an area, ways are part of out and inner lines. Now the relation is the main object, taking the same role as a multipolygon object in other gemetric schemes. Very hard to understand. No clear definition. Very error prone. Needs major work in all map renderers.
Proposal:
Seperate Geometry and Logical objects. Use a direct representation for geometrical objects instead of complex workarounds. Do not use the same objects in differnt places of a hierarchy with multiple meanings. E.g.
- Geometry (no Tags):
- <node>
- <line>
- Objects (with Tags)
- <poi>: has one or more <nodes>
- <way>: has one or more <lines>
- <area>: has one or more outer-<lines>, zero or more hole-<lines>
- Groupings and Relationsships
- <relation>: <all objects>
Better handling of sourcing ('source' tag)
We know that source of data and source date is a fundamental information when we use external sources (like aerial imagery) and not only local surveyed contributions. This information will be more and more important once OSM has reached a certain level of completion. We cannot avoid that but external sources may be outdated and it will then be important in the future to display quickly the existing contributions sources and dates, not only the date of the edits but also the dates of the sources like public data or aerial imagery. Otherwise we cannot avoid that arm chair contributors override older contributions surveyed locally or that recent aerial images or public data are better than very old survey.
Current solution is to put the tag source in the changeset or in each element, completly optional. Putting the source on the changeset is not perfect since a changeset can group different sources. Putting the source in all new elements is painful in editors and it will take a lot of resources.
The next API should provide an easy way to identify and group sources, make them more prominent in the protocol (at least at the same level as 'comment') and provide an easy way for OSM editors to retrieve and display the sources (and source date) in the history of elements. --Pieren 12:49, 8 April 2011 (BST)
- In reality this may be very complicated, as people blend in different sources, and those sources and dates may even differ on tag level. Mmd (talk) 09:52, 12 December 2020 (UTC)
Segments (instead of fragmented ways)
Speed limits, routes, bridges and other road features besides many other things force us to split ways. With a higher level of detail (turning lanes, side parking, ...) we'll end up in single roads being represented as hundreds of extremely short ways. The concept of segments would make it much easier to add road features, to build relations and would keep users from merging parts which ought not to be merged, thus resulting in far less broken relations (if you have ever been into route relations, you'll now what I mean, don't you?)
What is a segment?
A segment is a part of a way, denoted by the ways ID plus starting and ending nodes IDs. It can be tagged and added to relations just like a way. There can be parallel and/or overlapping segments of a way.
For example, think of turning lanes, and how elegantly turn restrictions could be implemented lanewise.
How does the API treat segments?
The API just needs to make sure that the starting and ending nodes or the way are not deleted as long as segments reference them. This is exactly the same mechanism as with relations.
I do quite understand the 'no new primitives' dogma, but have a look at the huge advantages!
--BorisC 01:28, 20 January 2012 (UTC)
- +1 - I thought myself to write the same proposal. There is a big problem that only gets bigger when we map with more details on ways. It will create small fragments that can not be handled easily.--Magol 20:47, 27 January 2012 (UTC)
- It appears that segments existed prior to v0.5 and "were removed, to simplify the data model." I agree such a goal was achieved at the expense of complicating editing. I wrote up a blog describing the same issue. --He the great (talk) 06:04, 10 August 2013 (UTC)
- Nevermind seems the old segments were the building block of a way, Unwayed segments. --He the great (talk) 16:07, 10 August 2013 (UTC)
- One can see this as a special variant of relationships. General relationships have a list of all its members, while segement only has a start and an end member.
- An alternative for segments to solve the problem with splitted roads, is that the API allow you to put tags on parts of a road. Today you can put tags on the nodes along a path, but not on a subset of the way. If you could put tags on subsets of a ways, the need for spliting up roads disappear. If you, for example, want to tag a bridge on a long road, you don't have to split the road. You only marks the start and end node and set bridge=yes.
- --Magol (talk) 22:22, 18 October 2013 (UTC)
Route primitive
Trying to map bus routes is quite an involved process, requiring you split lots of ways so you can reference just the parts of the road the bus actually uses. It would be useful if, like the Segment proposal above, we could have a primitive specifically for routes. Like other primitives it could be tagged, and would contain an ordered list of ways, and the start and end node that this route uses.
<route id="123"> <tag k="name" v="Bus route 66" /> <segment ref="456" start="78" end="90" /> <segment ref="457" start="90" end="150" /> <segment ref="560" start="150" end="654" /> </route>
The API would ensure that the route is continuous, that each segment shares a connecting node with the next segment.
Using lat/lon as a node id
Too much space is currently wasted on untagged nodes. Being essentially a lat/lon pair, these nodes store much additional information and require a level of indirection to e.g. gather nodes for a way. What if we use lat/lon instead of node id for this case? With our current coordinate resolution, lat+lon take 63 bits, which fits into 64-bit node id.
Pros:
- removes an indirection
- removes extra node data
- moves history of changing a way shape onto a way itself, where it really belongs
Cons:
- doesn't support transparent increase of lat/lot resolution
- makes it harder to maintain data consistency, e.g. it's more likely for a coastline or connected streets to become disconnected
- with extra help from editors and API (atomic changes), this may not be an issue
- hybrid variant (full-fledged nodes for tagged nodes and nodes used in multiple ways, and degraded latlon's for other nodes) may be considered
(chnav thinks:)
Vote for it :thumb:
- makes data processing much easier and less resource hungry, no mapped array required on client side;
- Having used 63 bits of 64 we can use one bit as 'connected_node' flag, then use special processing branch for such nodes in editor.
- Potential savings: 85% of nodes in a planet file could be removed. More detailed analysis: https://github.com/osmlab/osm-data-model/issues/1
Moderate suspicious uploads
Hold uploads identified as a problem by a scoring system (for instance mass deletions by new accounts) until another mapper approves them.
Geometric last modified date field
One of the biggest problem with current data model is that we can't know when an element was geometrically edited. See [1]
Suggest to add "last geometric change" field that would be updated recursively (e.g also parent element would be updated).
In node, this field will be updated if lon/lat has been changed, or when created.
In Way, when one of its nodes has been geometrically updated, if the order of the node references has been changed, or if node reference was added or removed from the way.
In relation this is a bit tricky as we don't know which members are geometric members or logic members. At least we can update this field on known roles/tags (e.g multipolygon) member updates, or just consider all members's "last geometric change" field. In addition any reorder, add or remove members would update this field.
Live edit server
Replace the current system of changeset-based HTTP requests to the database with a websocket server that enables live edits to entities.
Types of real-time recorded changes
- Geometries (you see instantly when someone has moved a node in your editor!)
- Tags (you see instantly when someone has changed a tag for an element in your editor!)
Initial OSM World Discord server discussion
Pros:
- Editors will not have to cache edits because they will be instantly committed.
- You can see what others are editing in the area during a mapathon and consult mappers who you are helping with changes.
- No more changeset conflicts!
- No more huge changeset areas!
- Better per-element history analysis without having to scrub through changesets!
- Might enable mappers/software to encourage marking sources for changes.
- Data consumers get access to the exact state of OSM database at any moment
- A map based on vector tiles that functions as a map and editor in one application would show edits for the editor themself and all users in real time.
Cons:
- No more changeset comments/tags. However, one could enable a system that allows for discussions to be created among a selection of edits made by a user.
--Lectrician1 (talk) 00:09, 26 January 2021 (UTC)
- Live editing was already present in Potlatch_1, back in 2010, although without websocket connection to immediately distribute changes. The proposal to move away from changesets gets us back to an API 0.5 state and its performance/scalability issues. Those issues are still present in today's API 0.6 'per element' endpoints. Mmd (talk) 19:54, 3 April 2021 (UTC)
- @Mmd: I also see the benefit of maintaining the changeset system with large upload diffs possible and better performance. Wikidata already implements a "live edit server" system and they are looking towards implementing an upload diff system for performance reasons. I think having both systems would be handy. --Lectrician1 (talk) 23:06, 6 April 2021 (UTC)
- Diff uploads support any upload size in a range of 1..10000 changes. You could upload your changes one by one, and they would be immediately visible to everyone who else requesting some data from the API. Remember that the concept of "changesets" does not correspond to a database transaction, i.e. you don't have to close a changeset for changes to become visible to everyone else. Uploading every single change has some disadvantages, nevertheless it's technically feasible without any changes needed on the API side. Mmd (talk) 19:06, 7 April 2021 (UTC)
- @Mmd: I also see the benefit of maintaining the changeset system with large upload diffs possible and better performance. Wikidata already implements a "live edit server" system and they are looking towards implementing an upload diff system for performance reasons. I think having both systems would be handy. --Lectrician1 (talk) 23:06, 6 April 2021 (UTC)
Improving Existing Features
Fine-grained diffs
- Benefits: Quicker uploads for those on low-bandwidth or high-latency connections. More concurrency when editing for large or complex elements.
- Problems: More complexity on the server and client.
The current diff upload format is OsmChange, in which each element to be edited must be present. This works very well for replication, as it means that many applications can process the diffs stand-alone and apply or re-apply them to a data source without problems. However, it doesn't work so well for editing, as a small edit to a very large way or relation requires a large upload.
A better, but more complex, solution would be to transmit only the changes to the elements in the diff upload (or what might be called a "patch" upload). For example, if the change consists of appending a node to a way there's no need to transmit all of the way's nodes, just the new node reference and its insertion position. This then enables a more relaxed locking system where it isn't necessary for the uploaded version number to strictly match the one that the server has, only to match what the server has on the part of the element which is being modified. This should allow more collaborative editing, particularly on very large relations such as country administrative borders, which can easily be being edited independently in geographically diverse areas.
I've a working prototype of some of these features, but more work is necessary to refine the details and implement the rest of the functionality. --Matt 14:32, 12 December 2009 (UTC)
Long-edit sessions get more and more dangerous as you always modify lots of relations (routes, multipolygons) and conflicts in upload are usually hard to fix with current editors. At lest for JOSM I see no changes for this in near future. A lot of users actually drop their work at this point and either restart or leave it.
- If JOSM cannot fix this, e.g. by using the diff approach outlined below, how can the API fix this without any UI? Mmd (talk) 09:49, 12 December 2020 (UTC)
There is a pretty easy solution, which could improve the situation a lot. Source code revision control system have the same problem, that multiple persons work at the same object. Instead of a file based approach they moved to a line based approach. This means changes in the same file are joined as long as they are xxx lines away (typically something around 5).
The same approach would work for relations. Removal or addition of new elements could be handled separately when the changed elements are far enough from each other. In this case both changes could be taken without conflict. Result would be a combined relation reported back to the editor. If changes are too near (or relation has been totally reworked), then a conflict can be issued as is done now.
Theoretical workflow (performance-killer version :-) for an relation upload:
- upload new relation
- if on server is not same version as new one
* save new relation into file new.rel * save server state into server.rel * save old version of server state into oldserver.rel * do a "diff -u oldserver.rel new.rel >diff" * do a "patch <diff server.rel" * if no conflict, upload patched server.rel instead of new.rel
As the diff can be made on client side before, we can reduce that a lot and also save lots of bandwidth (especially for large relations):
- Send a "diff -u" like relationupdate-request
- apply it and report conflict only when patching will not work, otherwise report new state.
BTW: The diff upload may also be an option for other large objects (ways) to save bandwidth (probably without the possibility to apply to non-matching version). --Stoecker 20:55, 22 November 2012 (UTC)
- The API supports compressed uploads these days. So bandwidth should be less of a concern. Mmd (talk) 09:46, 12 December 2020 (UTC)
GPX download in separated tracks
Right now, when downloading GPS tracks from the server, you get most of the (public?) tracks in a single GPX track <trk>. See : https://api.openstreetmap.org/api/0.6/trackpoints?bbox=3.1491280,45.8053798,3.1565094,45.8090295&page=0
It would be more useful for automated treatments (like averaging) to have them separated in several tracks <trk> inside the same GPX file or at least in several tracksegments <trkseg> inside a track. --Eric S 12:40, 6 November 2011 (UTC)
GPX upload API
This api is very good for form upload. For automatic upload it's no big problem but it would be easier with something like:
<all>
<description>blabla</description>
<whatever>blabla</whatever>
<gpx xmlns="http:/ ...gpx ...">
</gpx>
</all>
additional to multipart form upload.
Currently the API requires that track-points have a timestamp. This is not required by the GPX standard GPX 1.1 waypoint type. Some people do not like to upload tracks with timestamp information. There are repeatedly discussions in the community about how to fudge these values. Some people even publish corresponding scripts. This degrades data quality. Other people might, for this reason, not consider to upload tracks at all. This would reduce the overall number of tracks uploaded. I do not see any reason why one would want to have a timestamp at every track-point. It should be enough to know the age of a track. One could take the date the track was uploaded as a first approximation to the age of a track. In addition one might require the user to specify the age during the upload process. Hence, I would suggest to make the presence of timestamp information on track-points optional but require the specification of the age of the track as a whole. This should increase the reliability of timestamp values, in case they are present. --Schlauchboot 11:48, 20 March 2012 (UTC)
Current (v0.6) documentation are missing Error message documentation for the GPX upload API, please include this for v0.7 --Skippern (talk) 19:05, 27 March 2016 (UTC)
Enhance map call to return all ways intersecting the bbox
Currently, the map call only returns ways who have at least one node in the requested bounding box. For map editors like iD or JOSM, this can result in some ways to be missing in the map editor. The most common situations where this is occurring are long straight features such as railway lines in flat land, roughly mapped landuse areas, or artificial features such as country borders. OSM's editors have currently no way to know if any such feature might be missing (btw: iD already requests a slightly larger area than what is visible, but no amount of margin can assure that all ways are always loaded). Mappers could be making mistakes such as re-mapping these "missing" map features or irritated by unexpected behaviour such as map features suddenly popping in then data is refreshed during a map zoom or pan for example. The only solution would be if the OSM API not returned all ways which "intersect" the requested bbox (including those which have no nodes in the bbox). To simplify the implementation and speed up the API call by avoiding expensive geometry operations in the crucial map API call, the API could simply return all ways whose bbox intersects the requested bbox.
-- Tyr (talk) 13:16, 28 November 2022 (UTC)
Atomic Changesets
Currently when uploading changes it might be that changes aggregated in a changeset are beeing applied in "half" until the first conflict. Allowing this makes later pipelines with changesets pretty hard as a changeset means nothing other than a loose collection of changes which may be intermingled with other changes. So its impossible to reconstruct a changeset from the changeset information itself later in the replication. For this 2 things must happen.
- We must disallow changeset staying open which is possible right now.
- We must only accept changesets on the API which either apply all without conflict or roll back.
Flohoff (talk) 09:24, 6 March 2024 (UTC)
Replication files - referencing other objects by id _AND_ version
Change replication way and relation data structures to include way/node versions if referencing them from another data section. Currently ways only reference by node-id which is okay in a static context, but we are moving with changesets and modify data all the time, so its impossible to judge which node version this ways version references or referenced other than by timestamping. As we know changesets may stay open for as long as they like it makes it impossible to guess. This makes it impossible to reconstruct changesets from data pipelines on the replication files which is an issue in Q&A pipelines trying to identify issues with a specific changesets. This needs to be checked against User:joto data format/area/way node reduction ideas as obviously embedded nodes which only appear in a way dont need to be versioned. Flohoff (talk) 09:24, 6 March 2024 (UTC)
Removing Features
remove /relation/id/full call
The ability to download a relation and all its members lets many mappers create otherwise useless relations ("all park benches in Munich") just so they can download their pet dataset more easily. This has to stop - let's drop the /relation/id/full call. --Frederik Ramm 22:59, 12 October 2010 (BST)
- I think this is no longer a concern, as people would typically use Overpass API to get "all park benches in Munich" these days. 08:29, 22 April 2019 (UTC)
Simplify API Where Possible
It is possible to upload objects in a diff or individually. As far as I can tell, this is kept for historical reasons. In particular, the following endpoints could be deprecated right away:
- Create: PUT /api/0.6/[node|way|relation]/create
- Update: PUT /api/0.6/[node|way|relation]/#id
- Delete: DELETE /api/0.6/[node|way|relation]/#id
Each API feature should be reviewed for removal, unless absolutely necessary.
Also, information in a request should be specified once. In some cases, such as uploading to a changeset, the changeset ID is specified in the URL and in the diff itself.
Unclear requirements / unsolved issues
There are some problems which do not have a proposed solution so far. A solution has to be found.
Accuracy and elevation
Add new attributs 'height' and 'accuracy' in the node element. 'height' should be the raw WGS84 altitude. 'accuracy' is provided by some GPS or from some other data sources. It could be set by editors when the source is known (e.g. Yahoo imagery). Both could be null if unknown.
Editors could raise a warning if someone moves existing data to a new position when the new source is reported as a less acurate source than the previous one.
When altitude is known, we could avoid some "up/down" tags or validate data against DEM's. --Pieren 13:21, 26 March 2010 (UTC)
- A good start can be to allow GPX track store HDOP data, and allow users to filter that, if we also allow something in same line in the nodes, than we have the accuracy stored in the database. The question is than how we should handle the millions of nodes already in the database. Elevations should be handled completely different, i.e. as third axis co-ordinates. --Skippern 22:53, 15 May 2010 (UTC)
- Is this the same as adding a Z coordinate to nodes? BigPeteB 15:06, 13 July 2010 (UTC)
- Not clear how this is still relevant today, needs updated use case. Mmd (talk) 20:11, 18 December 2020 (UTC)
Bundle of ways
With the current API the bundle of ways-problem (i.e left/right turning lanes, cycle/parking lanes, sidewalk, center-line etc) could not be solved satisfyingly although a workshop has taken place. Possibly a new API feature could help. -- Tirkon 07:14, 23 April 2011 (BST)
Triangles
OK, so OSM did revolution GIS by stepping away from points, linestrings and polygons and using nodes and ways (and segments - oh, the old times).
So, if we're going to tackle the issue of areas and polygons, we should as well be innovative and not be caught on the same pitfalls GIS people do when working on 2D stuff (border armonisation, slivers, overlaps, etc). After all, we're computer sciencists, not arctards, for $DEITY's sake. Let's go to the basics. Let's go to the most simple 2D primitive. Let's use triangles.
Think of the world as a big triangle mesh (anyone that has ever seen a 3D wireframe model knows about this). A triangle is not a way: is just three nodes. And there are has to be books on algorithms to check triangle mesh consistency and topological stuff.
So, an "area" is just a relation of triangles. Eaaaasy peasy. Editing software would be able to display all triangles, and let the user click on them to add them to the area relation, or something like that. Checking areas inside areas should be dead easy.
I do agree that a new data primitive is a pain in the ass for the developers, but this triangle idea might be worth considering. --Ivansanchez 10:41, 2 February 2010 (UTC)
Relates to: Area/The_Future_of_Areas --> The_Future_of_Areas/Triangles
Curved segments for ways
Currently, way segments are straight lines. But many objects in world are rounded - a curve in railroad track or road of some radius.
So people either use lot of nodes to achieve good precision at cost of space, or they use just a few nodes - at cost of accuracy.
- Could be done using bezier curves. X-Plane 10 uses OSM-data to create realistic roads and traffic. So they implemented a tool that creates bezier curves from OSM data. Of course I don't suggest to convert the existing data but to implement something like bezier curves (could be done with a relation if existing structures should be used) so users can create smooth curves. Tools like JOSM could implement functions to create a way using nodes first, then select some nodes, press "create curve" and JOSM tries to optimize these nodes in matters of node count using bezier curves. Then the user can tune the curve and upload it --LetzFetz 23:51, 30 August 2011 (BST)
Example
This way:
<way ...> <nd ref="A" /> <nd ref="B" /> <nd ref="C" /> <nd ref="D" /> <nd ref="E" /> </way>
Could become a way with segment between C and D forming a circle arc:
<way ...> <nd ref="A" /> <nd ref="B" /> <nd ref="C" /> <nd ref="X" type="circle" /> <nd ref="D" /> <nd ref="E" /> </way>
Technical details
Technically, every node reference will get one extra flag in database (is/is not a circle point)
While having some more universal curves, like Bézier curves, could be better, these may confuse beginners, as it is not always simple to manipulate control points to get desired curve. But I think everybody understand circles.
- Surveyors rarely use curves more complex than circular arcs - if the people who set out the features we map don't use Bézier curves themselves, there's not much point in spending the extra effort. However, highways and railways often use clothoids, although only hardcore CAD packages support them natively. Ploppy 19:40, 2 October 2011 (BST)
There are two variants how this could be implemented:
- the control point will be center of the circle - easier to compute, worse "backward" compatibility
- the control point will be a point on the arc - more complex for software to compute the circle arc, but easier to manipulate for the user, there is some backward compatibility - 0.6 software would ignore type="circle" tag and get just a much jaggier line (control point lies on the circle), though in correct location.
- ISO 19107 and GML use the second representation. Ploppy 19:40, 2 October 2011 (BST)
In both cases software can exactly calculate the circle arc (except for invalid data, like two of the points having same location)
Bézier curves
Control points of Bézier curves can be stored the same way. Example of the most commonly used quadratic arc (two control points):
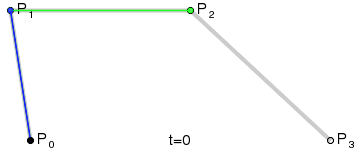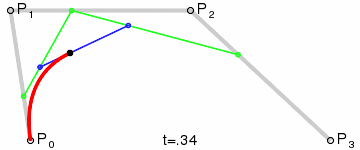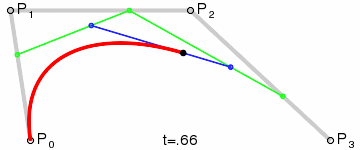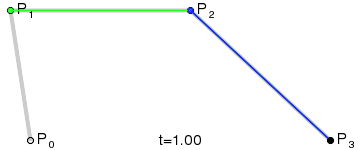{kind=link}
<way ...> <nd ref="A" /> <nd ref="B" type="bezier" /> <nd ref="C" type="bezier" /> <nd ref="D" /> </way>
This notaton can handle any lower or higher order Bézier curves. Example of a cubic arc (one control point):
{kind=link}
<way ...> <nd ref="A" /> <nd ref="B" type="bezier" /> <nd ref="C" /> </way>
Example of a quartic arc (three control points):
{kind=link}
<way ...> <nd ref="A" /> <nd ref="B" type="bezier" /> <nd ref="C" type="bezier" /> <nd ref="D" type="bezier" /> <nd ref="E" /> </way>
Also handles a special situation where an arc has only one control point at one end of and other end does not have a separate control point. In this case other control point is same ad end node:
<way ...> <nd ref="A" /> <nd ref="B" type="bezier" /> <nd ref="C" type="bezier" /> <nd ref="C" /> </way>
This notation is backward compatible with API version 0.6, similar to circle point.
I think support of arcs (circle, Bézier, clothoids) could increase quality of maps producable from OSM data. Roads, especially on mountains have more arcs than straight lines.
In order to create a large scale high quality printed map from OSM data polylines should be converted to arcs. Such a conversion is not trivial because data does not contain information which segments are really straight and which are arcs. Therefore automatic conversion of polylines to arcs often fail.
When surveying a road in the mountains under leaves where road is not visible on aerial images and GPS reception is also poor, I mark points where straight part ends and an arc begins. Also mark inflection points where left-turning arcs switches to right-turning arcs. This helps me to draw more accurate shape of the road.
Information about arcs and straight lines is lost because I can only set nodes in the way but can't mark them as straight-to-arc or inflection points. Placing a tag to the node is ambiguous if node is part of several ways. Intersections are often at inflection points.
When mapping a road that has many small arcs I use at least 3 points between inflection points. Using cubic Bézier arcs only one node would be enough to describe the whole arc instead of 3 (or more). It would save storage while the output quality would be much better. (Kolesár March 2016)
- How will this work, when a user it splitting a way into two ways? Mmd (talk) 09:35, 12 December 2020 (UTC)
- Move this to "unclear", as the need for having such overly complex stuff isn't obvious. After all, we're not trying to compete with some CAD packages in OSM. Mmd (talk) 11:38, 13 December 2020 (UTC)
Done - Solutions already available
API 0.6
Solving complex (and easy) problems by OSM sandbox/playground
Different from Wikipedia we have neither a common Sandbox nor user-owned sandboxes (1 2) in OSM. This detaines us from finding solutions for such complex problems as described above - alone or in a collective. The Try And Error principle is simply not possible without harm to the original database. A solution could be a different database of a "mini-earth/planet". However the big disadvantage is, that not every OSM tool and application will run with it. It could be helpful to reserve a "hidden" part of the normal database for this purpose. This could be i.e. at latitude 0 to -1 North (notice the !!minus!! 1). The API delivers this imaginary area instead of the real 0 to +1 South while converting 0 to -1 North to 0 to +1 south only then, if the user has set an application independent flag before. Thus the "hidden" area will show up in every application as soon as the flag is set.
This helps us to find solutions and to test them in every application like it is done in Wikipedia. It would also help beginners to discover complex constructions like i.e. parent and child relations. User reserved parts could explane complex examples for beginners. This is not possible at present because the examples in the real database could be changed meanwhile.
If the hidden area is not possible as described for any reason, another API solution has to be found which works with every application. -- Tirkon 08:07, 23 April 2011 (BST)
- Dev box is available, you can play around with it all day long, create complex relations, etc. Having a reserved part of the production db does not seem feasible. Mmd (talk) 16:30, 11 December 2020 (UTC)
Download/Upload compressed data
Due to XML's redundancy, it has a very high compression ratio, so why not send and receive data in a gzip file ? When uploading such a file, the servers processes the data and returns all conflicts that need some more work (as JOSM do, some of them can be solved automatically).
- Server already supports HTTP compression. No need for gzip files. -- Firefishy 09:14, 26 July 2010 (UTC)
- For uploading changes, see https://github.com/openstreetmap/operations/issues/193 Mmd (talk) 12:24, 15 April 2018 (UTC)
one request should deliver all nodes, ways, relations from a bbox
I think it's cumbersome to send out 3 requests to get data for ways, nodes and relations. i want to be able to send one request for a bbox and get all affected elements in one xml file. --Flaimo 12:04, 20 April 2011 (BST)
- Something the /api/0.6/map doesn't do? Alv 07:43, 27 April 2011 (BST)
Format agnosticism
The API is not really very MVC - there's only one view, XML, and the serialisation code is currently in the controllers rather than the view. Ideally the same API calls should be available via XML, JSON, AMF (etc.) views. May need some thought as to implications for Rails performance.
- There is a json format for geo data. It's called geojson. geojson does not give all the possibilities the OSM-XML format has. With geojson it is not possible to share a node. --Robotnic 12:24, 3 July 2011 (BST)
- Moving XML, serialization to the view is currently ongoing. Mmd (talk) 19:45, 21 April 2019 (UTC)
- Moving to done on wiki page, XML/JSON generation via builder, remaining parts of JSON support handled in Github issue instead.
Overpass API
Multipolygon bbox
Allow for border relations to be used as bbox when downloading an area. This will allow one to download only a certain municipal instead of making several (often overlaping) downloads to cover the same area.
+1 from me! --Lulu-Ann 16:14, 16 December 2009 (UTC)
+1 from me! --Bahnpirat 14:57, 17 March 2010 (UTC)
Polygons from relations still have trouble and will so for a long time. See above at areas. I would suggest rather a map call to download from a polygon with explicitly stated coordinates.
- This is possible with Overpass API--Jojo4u (talk) 23:43, 29 September 2016 (UTC)
Download of all data inside a relation (or admin. boundary)
Today, to get all data inside a relation in a map.osm file, I need pgsql and osmosis. I'd pleased if I can download map.osm (in the export tab os the site) of a relation, in the same way I do with a BBox.
- Same as Multipoligon bbox? --Skippern 19:32, 17 December 2009 (UTC)
- Not the job of the API (AKA WONTFIX). Client-side software (I'm thinking JOSM) can fetch the relation, and calculate many small bboxes. JOSM already can do this for long ways or GPX traces, so areas should be doable. --Ivansanchez 10:41, 2 February 2010 (UTC)
- Already possible via the OSM mirror plugin + overpass queries (though usability can improve as always). --Sanderd17 (talk) 16:16, 11 February 2015 (UTC)
Make it easy to get complete state of ways or relations at a date
Currently ways and relations only refer to their members by id. meaning that if a change is performed on way members or relation members the way or the relation is not changed itself. So the way or the relation can stay at version 1 whereas a lot of changes has been done on their members. I think it could be interesting to have something like
- GET /api/0.6/[ways|relations]/#id/full/#date (return all way/relation members in the state they were at the date provided in parameter )
Currently I perform that in my monitoring tool by requesting the way/relation history to get the state corresponding to the date and then require the history of each member to get the state corresponding to the date what make a lot of API request. I guess that such feature should have an easier access -- [[User:Quicky|quicky] 2:35, 3rd Jan 2013 (UTC)
- Can be accomplished via Overpass API, see http://overpass-turbo.eu/s/xTU Mmd (talk) 12:19, 15 April 2018 (UTC)
Tag Search as a Top Level Feature
Xapi provides a very powerful search facet that would offer great benefits as part of the main API: node or tag search. There are many interesting operations to perform on "all water fountains in this bounding box", for example. Tag search should allow a much larger bounding box compared to any other operation, or perhaps support a limit/offset feature (return the first 1000 drinking fountains... the next 1000... etc)).
- Top n is supported by Overpass API, only skipping first n isn't possible (yet) Mmd (talk) 08:43, 22 April 2019 (UTC)
Using a polygon to download data
Other than downloading areas or multipolygons, a nice addition would be to download everyting inside an arbitrary polygon.
Like the bbox predicate, but extended to use more edgepoints: poly=[52.36,4.88,52.36,4.92,52.39,4.90] would download a triangle in the center of Amsterdam.
- It is already possible with Overpass API, see language guide:
(
node(poly:"52.36 4.88 52.36 4.92 52.39 4.90");
<;
);
out meta;
Make it easy to keep track of parent objects
Add a set of API calls that allow an editor to keep a list of all parents for a certain object:
- for a node have a list of all ways that contain this node
- for any object have a list of all referring relations
Here is, where we currently lose the thread:
- GET /api/0.6/[node|way|relation]/#id (download individual objects)
- GET /api/0.6/[nodes|ways|relations] (download missing members of a relation)
- GET /api/0.6/relation/#id/full (download all relation members)
- GET /api/0.6/map?bbox=... (for nodes outside of the bbox and for parent relations of relations that have physical members inside the bbox)
(There are calls to explicitly get the parents for an individual object, but would cause too much traffic to use it each time.) -- Bk 07:13, 13 May 2010 (UTC)
Support to download queries like addr:*=*
Support to download queries like addr:*=*, to support subtags.
- Can be done with Overpass API--Jojo4u (talk) 23:31, 29 September 2016 (UTC)
SQL queries
As things are, importing the planet into postgres involves converting it to xml, uploading and downloading huge files, parsing some 170 GB of xml with osmosis and osm2pgsl only to arrive at a database that resembles the original, but is not the same as the original. And all this when we could just issue an SQL query and get the raw data that we need, no conversions involved. This would be particularly useful to those who need relatively large areas, but not the whole world or not all of its features.
A hot standby db with world read access to the relevant tables should be all it takes, and would be doubling as disaster replacement for the master at no extra cost.
- I'd say this isn't necessary any more thanks to Overpass. —M!dgard [ talk ] 10:37, 29 January 2018 (UTC)
Retrieve only data between certain dates of changeset ids
Add parameters to "GET /api/0.6/map" that filter out object versions that were created outside of a given date (or changeset id) range. The output would be the same as for the existing call, or could also include the full history of downloaded objects.
This would simplify history review a lot.
- This requirement isn't entirely clear. /map only returns the latest version of an object. Overpass API can be used instead in this case to check the timestamp() of each object in a bounding box, and discard those objects outside of a given time range. It's not clear how this relates to the history of downloaded objects, and why we want to return history for all objects in a bounding box. It would amount to a huge amount of data. Mmd (talk) 11:35, 13 December 2020 (UTC)
Wikibase / Wikidata
Classes
There is little information about semantics in the database. As a result, there are dozens of ways of tagging a cycleway. Building a renderer stylesheet gets very complicated. Also the software to edit the map has to have a lot of implicit knowledge. And there are a lot of contradictions and inconsistencies between the different definitions, to the wiki or in the usage in different parts of the world. Take e.g. the notion Trunk: this refers in the UK to the connectivity of the road and their funding. Outside UK, e.g. in Germany, the notion is used for roads with this traffic sign. Public transport is organised in Germany within transport associations while those rarely exist anywhere.
{kind=link}
The idea is to have a declaration in the database for the semantics of a tag within a certain region:
<class>
<pivot k="highway" v="almost_motorway"/>
<desc lang="en">
Use this value for roads with traffic sign http://upload.wikimedia.org/wikipedia/commons/c/c6/Zeichen_331.svg
within Germany.
</desc>
<desc lang="de">
Kraftfahrstraße bzw. Kraftfahrzeugstraße.
</desc>
<bounding-polygon>
(Rough borders of Germany)
</bounding-polygon>
<implies k="highway" v="trunk"/>
<implies k="pedestrians" v="no"/>
<implies k="bicycles" v="no"/>
</class>
<class>
<pivot k="highway" v="almost_motorway"/>
<desc lang="en">
Use this value for roads with traffic sign http://upload.wikimedia.org/wikipedia/commons/c/c6/Zeichen_331.svg
within the Netherlands.
</desc>
<bounding-polygon>
(Rough borders of the Netherlands)
</bounding-polygon>
<implies k="highway" v="trunk"/>
<implies k="maxspeed" v="100"/>
<implies k="pedestrians" v="no"/>
<implies k="bicycles" v="no"/>
</class>
|
Thus, editing agents can just offer classes that apply to the edited region and don't need to have their own semantics. They can even offer coherent suggestions for values on tags. Things like the per-country speed limits can easily be integrated. Renders no longer need to care for subtle differences. The tags on nodes, ways and relations could be straightforward normalised according to the rules while parsing. Thus, stylesheets can get much simpler.
- This kind of information can nowadays be found in Wikibase: https://wiki.openstreetmap.org/wiki/Item:Q4980 Mmd (talk) 19:38, 21 April 2019 (UTC)
Default values for an area
In Relations/Proposed/Defaults is a proposal how to tag default values for relations mainly areas defined through a boundary. This includes things like country specific traffic laws, state specific holidays, city/town specific regulations and other regulation. While this proposal night not be the best way to handle area specifi regulations, it shows the need to handle implicit informations. See also #Classes in this document.
Out of scope for OSM editing API
The direction problem
With the most editors it is very easy to change the direction of a way accidentally by one click. This destroys all the depending information like i.e maxspeed:forward/backward (left/right, ...) or relations like routes. The reversing is very hard to observe and in many cases only for those, who check and compare the way carefully in reality. Thus in rural regions the fault could survive years. Some editors i.e Potlatch do not make this destroying visible for the reversing user. This is simply impossible because OSM has no defined set of tags and relations. Furthermore in case of mapping traffic-signs (i.e maxspeed, town sign) you need a direction for this node which is not possible at present. Thus API 0.7 should provide a solution.
Possibly the direction of a way could be given automatically at the moment of creation and not by the user and should not be changeable. I.e this could be done by giving a direction only within 180 degrees from starting node in west to ending node in the east at the moment of creation. Then i.e. the direction of a oneway could be given by a forward/backward tag. This would at least solve the direction problem for ways but not for nodes. Latter solution has to be found. -- Tirkon 07:14, 23 April 2011 (BST)
- This issue needs to be solved in the editor rather than the API, and many modern editors already take care of this. Mmd (talk) 16:33, 11 December 2020 (UTC)
geometry compression
If somebody wants to show the European motorway on a (small) map, at the moment it is not easy get the vector data. There should be a lossy compression that could be implemented in steps:
- Take only every second/fourth/eight/... node of a way. Maximum compression would be start and end node.
- Ignore nodes if they are too close together.
- Find a more mathematical way to describe the way. A spline could aproximate many points.
- Play with zoomlevel, compression rate, accuracy
Why do this?
A nice compression would allow to use the map with an offline database. People would like to have offline maps on a smart phone.
--Robotnic 09:26, 4 July 2011 (BST)
- You can already do this by processing the data from the OSM planet file yourself before giving it to your users. Some people already do that. GPSBabel already has the ability to do what you want for GPD traces, I'm sure the same or similar algorithms could be applied to OSM data. Smsm1 09:58, 22 August 2012 (BST)
- Proving data with geometry compression is not the purpose of an OSM editing API, this should be provided by some external service. Mmd (talk) 08:27, 22 April 2019 (UTC)
Geographic regions
There is the need to model geographic regions (mountain range, valleys, lowlands, plateau, ...) which might not be connected to administrative boundaries (the Upper Rhine valley belongs to Germany and France). These regions might have a hierarchical ordering in terms of regions and subregions (the Alps consist of several mountain stretches, each with its own name). see also Relations/Proposed/Region
Non feasible / actionable proposals
Destroyed relations
Relations can be destroyed by changing its members without any further notice of the editor and user. Because OSM has no defined set of tags and relations this is simply impossible. I.e. the splitting of ways because the end or a turn-off of a route-relation is nearly unvisible in an editor and forces the user to join them, if he has to edit around the splitting-node. Again this could moreover change the direction of one of the joined ways, which makes problems with directional tags and relations (see above). Possibly a new API feature could help. -- Tirkon 07:14, 23 April 2011 (BST)
- This needs to be handled by the editor apps. There's no way to integrate tagging specific logic into the API that changes all the time. Mmd (talk) 09:31, 12 December 2020 (UTC)
Anonymous edits
A lot of users just wants to edit a smal part of the map and not have to register. Why not do like wikipedia and allow anonymous edits up to a limit. The ip address will be stored and after x amount of changes to objects the ip address will be banned and the user will have to register to contribute more. This is an alternative to openstreetbugs and may not be needed if openstreetbugs is more visible to the public.
- Disabling Anonymous edits was a thought-out decision in 2007. The discussion from that time should explain the reasons. Alv 18:08, 28 February 2010 (UTC)
- This is not the same type of anonymous edits. I im sugesting to allow users to edit the map with limited access or to upload tracks without the hustle of creating an account. Just like wikipedia. Gnonthgol 18:30, 28 February 2010 (UTC)
- Anonymous Editors should be able to edit their own view of the world. If somebody adds a building he will have this building on his map until he deletes the browsercookie.
If the user want to contribute to OSM he should be able to sign up after editing. If the user finaly has an account he can send for example his collected gpx files to OSM. The API needs no change for that.
- JOSM sort of have it implemented already (the user can edit as much as he like, but only upload after he have registered). Maybe Potlatch should have a similar approach? Let people edit as much as they like, maybe even save it as an OSM-diff file, but only apply the changes after registering? (Obviously not API related) --Skippern 02:09, 22 March 2010 (UTC)
- We want users to be available for questions by the community, which cannot be ensured when using anonymous edits. -> Moving to not feasible/actionable. Mmd (talk) 20:03, 9 December 2020 (UTC)
Status During Diff Uploads
See osm-dev thread.
Ways are just simple relations
Why not remove ways as a primitive and implement them as a subset of relations? This can be done transparent of the user by having a sort of hidden this_relation_is_really_a_way=yes and serving out just those tagged with it when user queries for ways. Hm... This wouldn't even require an api change, but still... --Gorm 15:05, 7 June 2010 (UTC)
- this_relation_is_really_a_way would imply: 1) only nodes may appear as members, and 2) members (nodes) do not have a "role". So although you may think of ways as a special subclass of relations (or they may be just that in a mathematical sense), they form such a strongly restricted subclass that it is wiser to implement them separately, which also avoids some overhead. -- Oli-Wan 07:48, 6 November 2010 (UTC)
- What would be benefit of this insanity? Bulwersator (talk) 12:28, 2 November 2013 (UTC)
No new primitives
Sometimes "leaving the hell alone" is a virtue.
We have nodes, ways, relations. They can be used for pretty much anything you like. We have data integrity courtesy of changesets. Any further change to the data model distracts our limited pool of developers from important stuff (UI, performance) solely to satisfy architecture astronauts. Even changes that seem trivial to one developer, e.g. ordering relations, can be immensely disruptive to other projects whose UI doesn't work in the same way as that of the original developer's project.
More new primitives
We need to invent new primitives to make sure that only the best software survives - software with a strong enough developer community to embrace the change and the new opportunities it brings. Software whose programmers whine about having to make a change deserves to die, or be banned. We're too young for a wholesale dismissal of change.
- I like the concept of Circus Maximus or Colosseum where "codiators" (mix coder/gladiator) are fight against virus represented by lions.. no better: dragons! --Bahnpirat 15:04, 17 March 2010 (UTC)
Public transport
The mapping of public-transport has a long history in OSM. Different solutions have been developed. Two workshops have taken place. A special mailing list was created. But with every of the presented solutions people had collywobble. They were too complex, hard to understand and did not satisfy all needs. Possibly an ingenious API feature could help. -- Tirkon 07:14, 23 April 2011 (BST)
- This is not actionable as it stands, as it does not describe a way forward. Mmd (talk) 16:30, 11 December 2020 (UTC)
Directions, destroyed relations, bundle of ways, public transport
Possibly many of the problematical details have the same core and thus could be solved by one ingenious API feature. -- Tirkon 07:14, 23 April 2011 (BST)
Make points of interest single-noded ways
At the moment points of interest can be mapped either as points or as ways, which makes life more difficult for users of the database. If the points become ways with only one node, they can be converted to full ways as they are mapped more thoroughly and we can get rid of the concepts of tags on nodes and of nodes being members of relations.
- Can be done already today (but isn't widely used). Topic for editors, not relevant for API 0.7. Mmd (talk) 20:19, 9 December 2020 (UTC)
uniqueness in relations
An attribute should be set in the relation element to enable/disable a uniqueness constraint on relation's members when duplicate values are not welcome. Editors and contributors are not aware about this possibility and this creates not desirable duplications where this possibility has been introduced for a very small subset of the relations. --Pieren 13:21, 26 March 2010 (UTC)
- Use case not clear, or why this should be handled by the API rather than an editor app. Mmd (talk) 20:49, 9 December 2020 (UTC)
4th Dimension
Include date and time or date intervals (time intervals are included) in keys and values:
Example:
name=Avinguda Francesc Macià
name:1960=Avenida del General Yagüe
name:1939-1978_12_06_14_59=Avenida del General Yagüe
Format will be yyyy_mm_dd_hh_mm.Intervals are separated by -
Date A.C.= will be negative dates as you can see on OHM We need also some aditional tags like:
highway=historical
historical=roman_roads
construction_date=-118-400
It will be something like that:
construction_date=-118-400
highway=historical
name=Via Domitia
historical=roman_roads
source=Information Panel Pont Romain, Route du Brest, Carhaix-Plouguer
And also we need a key to express the different calendar structure (nowadays OSM is strong in Europe and USA, with christian date structure but in future what about other calendar structures)?
calendar_structure=christian
Also we can include decades:
name:1960s=Avenida del General Yagüe
- This sounds like tagging and not API. Date_namespace proposal is covering this.--Jojo4u (talk) 00:12, 30 September 2016 (UTC)
Replace output of /capabilities request
In API 0.7, capabilities should be replies as simple name/value pairs, like so:
<capabilities>
<capability name="min_version" value="0.6"/>
<capability name="max_version" value="0.6"/>
<capability name="max_area" value="0.25"/>
<capability name="max_tracepoints_per_page" value="5000"/>
<capability name="max_nodes_per_way" value="2000"/>
<capability name="max_changeset_size" value="50000"/>
<capability name="timeout" value="300"/>
</capabilities>
Notes:
- this is a minor, cosmetic features. If implemented, it would contribute to simplify the API.
Gubaer 16:57, 5 December 2010 (UTC)
- I moved this to non feasible/actionable, as the capabilities format has been extended in the meantime to include completely different information as well, such as imagery policy information. Storing this kind of information as key/value pairs does not seem worthwhile at all. Mmd (talk) 20:07, 9 December 2020 (UTC)
Immutable objects
Instead of having revisions of objects, have immutable objects and let them point to their own ancestors. This will solve origin problem in way splits and merges. Will also allow easier reverts. When a object is modified, it will be invalidated and a new copy will be created with new attributes.
This causes serious issues by cascading updates, e.g. as a change to a node would invalidate any way and relation using that node (because they point to an object id which is no longer exiting after changing the node). Then again, changes to the way would invalidate relations and possibly other relations.
Better precision
Right now, the database stores data as 32-bit integers. And that's perfectly fine, because it Just Works(tm).
However, the method is so dump (just multiply the epsg:4326 coordinates by 10 million) that there is quite a bit of precision loss in the process: the maximum precision OSM can achieve is around 2 centimeters. And there are lots of space wasted (e.g. from -217 to -90 and from +90 to +213 latitude).
2 centimeters may not seem like a big deal, but some applications (e.g. cadastral maps) must be accurate to less than one centimetre. There should be some way to pack both the lat and long in a 64-bit field, in some way that doesn't suck completely, and makes a better use of the available 'address' space. Alas, this is so low-level that can only be tackled at the API and DB. --Ivansanchez 10:41, 2 February 2010 (UTC)
I don't think you can gain much. Longitude assumes values between -Lon_Max and +Lon_Max, where Lon_Max is Pi. Latitude assumes values between -Lat_Max and +Lat_Max, where Lat_Max = Pi/2. If you map these intervals to [-Int_MaxValue, +Int_MaxValue], you have Lon_IntValue = Lon * (Int_MaxValue / Lon_Max) and Lat_IntValue = Lat * (Int_MaxValue / Lat_Max). Hence, the resolution would be Delta_Lon_IntValue = 1 = Delta_Lon * (Int_MaxValue / Lon_Max) and Delta_Lat_IntValue = 1 = Delta_Lat * (Int_MaxValue / Lat_Max). The resolution on the meridian is then Delta_Y = R * Delta_Lat = R * ( Lat_Max / Int_MaxValue ), where R is the radius of earth. The resolution on parallels depends on the latitude. On the equator it is Delta_X = R * ( Lon_Max / Int_MaxValue ). For 32-bit integers one has Int_MaxValue = 2^31. Hence, the resolution on the meridian is about 4.7 mm. On the equator the resolution is about 9.3 mm. About 60 degrees away from the equator, the resolution it about 4.7 mm in both directions. This is close to the current solution, which uses a factor of 10 million for latitude and longitude in degrees. This makes a factor of 180 * 10 million as compared to 2^31. Hence, the improvement on the equator would be 2^31 as compared to 180 * 10 million, or a mere 20%. On the meridian, on the other hand, one could improve the resolution by a factor of about 2. Note, that this is only one bit, which you cannot cut in half. I don't think, that you can get any better than that. --Schlauchboot 20:04, 20 March 2012 (UTC)
Isn't increasing the precision pretty (well actually totally) pointless, given that the changes from just a year of continental drift are already larger than any improvement in precision that we could acheive? If any change at all should be contemplated, wouldn't it make a lot more sense to change to appropriate continent wide coordinate systems (ETRS89 etc)? SimonPoole (talk) 11:25, 21 November 2013 (UTC)
One additional issue with too much precision: Downstream tools will have problems in dealing with high precision floats. For example, with PostGIS some operations need ST_SnapToGrid or post-processing with ST_SetPoint to get expected output rather than very slightly off-target. Snapping/setting are currently reasonably safe, however, this only due to the fact that geometry anomalies are prevented by the low precision of OSM data (with higher precision object simplicity would no longer be assured). --Ij (talk) 09:50, 11 October 2014 (UTC)
Replace DELETE /api/0.6/[node,way,relation]/#id
API 0.6 requires a delete request to include an entity with an XML fragment describing the object to delete. Although the HTTP specification isn't absolutely clear whether entities are allowed in DELETE requests or not, most available HTTP client libraries (at least in the Java world) don't support them:
- JOSM relies on the HTTP stack provided by the Java SDK. It can't send an DELETE request including an entity and it emulates it with a diff upload
- Apache HTTP client 4 doesn't support an entity in a HttpDelete request
In API 0.7
- don't support DELETE /api/0.7/[node,way,relation]/#id including an entity
- introduce DELETE /api/0.7/[node,way,relation]/#id/#version?changeset=changesetId
- deletes the object in the changset changesetId provided the changeset exists, is open and is owned by the user submitting the delete request
- #version is the object version to delete. If #version < current version on the server, an error is replieed
- #id is the id of the object to delete. As usual, an error is replied if an object with this id doesn't exist or if it is already deleted
- Single object operations should be discouraged in API 0.7, not replaced by another single object operation, which is meant to overcome some historic Java client issues. Mmd (talk) 20:43, 10 December 2020 (UTC)
remove the atomicity requirement from the POST /api/0.6/changeset/#id/upload call
This API call (diff upload) is defined to operate 'atomically'; either all the changes in the OsmChange document uploaded are applied, or none are applied. The requirement for atomicity makes it difficult to scale the API server horizontally by distributing map data across multiple machines in a cluster. Further, as OSM grows, we would need to serve map data from multiple (geographically dispersed) data centers. In such a context, the need for 'atomic' changes would be even more of a hindrance. Jkoshy 05:59, 24 November 2010 (UTC)
- diff upload is not designed at all to deal with partial updates, this is not feasible at this time. Mmd (talk) 22:34, 9 January 2020 (UTC)
Everything is a relation
We should move back to segments based geometry of API 0.4 and group (*not* categorize) items relationnaly. For example, a Street relation could have:
- Its name
- Its ID in other databases for cross-reference (such as WikiData)
- Its "wire geometry" for routing with all the segments (currently streets ways are split according to tags distinctions such as lanes, parking, public transportation, category and so on)
- The physical footprint of the street on the ground…
- …which could be divided lane-per-lane
- The buildings linked to the street with the according buildings numbers
- The trees linked to this street
- The parallel ways in case there are some (for example, when it's split)
It would also be more flexible for having other kind of models such as public transports routes: each usage only take the segments it wants without arbitrarily splitting ways.
This would ease the processing of all the data related to a street which is way more than we currently have in a simple way. For example, this is not the "Avenue des Champs Élysées", it's only a tiny part Nominatim returned me when I looked it up.
In the other hand, we would need to rework a lot on the editors as relations are currently sometimes tricky to edit.
- This is by far too complicated and fragile. After all, OSM is a geographic database, hence there's no need to associate trees with a street, etc. Mmd (talk) 11:27, 13 December 2020 (UTC)
Fun stuff
All Tags in Chinese only
All tags should be translated to Chinese, and only Chinese characters should be accepted for tags in the future.
- Klingon would be better
- I prefer Braille, don't care if Klingon Braille or Chinese Braille.
- Tengwar to be default charset in API and renderers.
- -1 for Klingon. It is so passé. We need Na'vi names. --Ivansanchez 10:41, 2 February 2010 (UTC)
- Why not Baybayin? -Ianlopez1115 12:57, 4 March 2010 (UTC)
- I did some experimenting with tags in Lojban, e. g. pluta=* + cmene=Lorem Ipsum Street for a road. —Mabull alias Go Wild! Fan alias green guy! 13:12, 30 May 2023 (UTC)
See also
- User:Frederik Ramm/Ideas for API 0.7
- Contributors_functionalities_wishlist - building a shorter list with comments on other's ideas (many ideas taken from here)
- User:Zverik/API 0.7 Proposal — another short list of suggestions which are relatively easy to implement and would improve user experience
And more generally...
- Develop - the main OSM development portal
- Bugs - links to various bug tracking lists
- Top Ten Tasks - Major development initiatives in progress